고정 헤더 영역

상세 컨텐츠
본문
반응형
데이터 전처리 과정은?
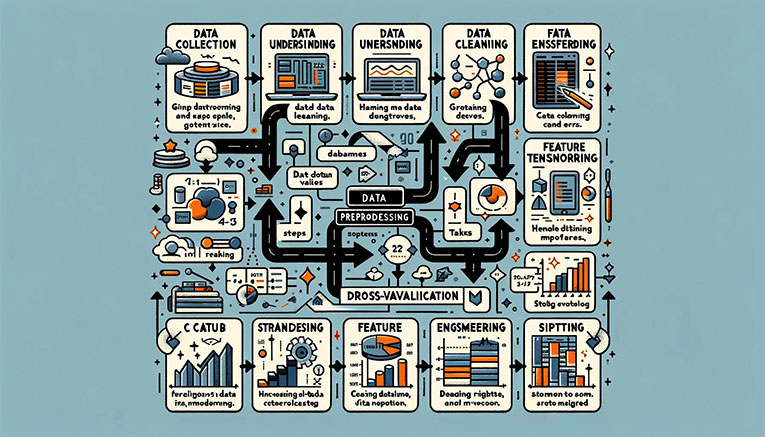
현대 사회는 데이터의 시대라 불릴 만큼, 데이터가 모든 분야에서 중요한 역할을 하고 있다. 데이터 과학은 이러한 데이터를 분석하고, 유의미한 정보를 추출하여 의사결정을 돕는 중요한 학문이다. 그러나, 데이터를 단순히 수집하는 것만으로는 충분하지 않다. 데이터가 유용하게 사용되기 위해서는 반드시 거쳐야 하는 과정이 있는데 그것이 바로 데이터 전처리이다. 데이터 전처리는 다음과 같은 과정을 거친다.
가장 먼저, 데이터 전처리는 데이터를 수집하는 단계이다. 오늘날 데이터는 다양한 출처에서 쏟아져 나오고 있다. CSV 파일, 데이터베이스, 웹 크롤링, API 등을 통해 수집된 데이터는 일관성이 없고, 불완전하며, 때로는 잘못된 정보가 포함되어 있다. 이러한 데이터는 그대로 사용하기에 부적합하며, 따라서 데이터를 통합하고 정리하는 작업이 필요하다.
데이터를 수집하고 나면, 다음 단계는 데이터를 이해하는 것이다. 이는 데이터를 시각화하고 요약 통계를 계산하여 데이터의 기본 구조와 패턴을 파악하는 과정이다. 이러한 초기 탐색은 데이터 분석의 방향을 잡는 데 중요한 역할을 한다. 또한, 각 변수의 의미와 데이터 유형을 이해함으로써, 데이터의 본질을 파악할 수 있다.
반응형
데이터 이해 단계가 끝나면, 데이터 정제 작업이 이어진다. 데이터셋에는 종종 결측치와 이상치가 존재한다. 결측치는 데이터를 분석하는 데 큰 장애물이 되므로 이를 적절히 처리해야 한다. 이상치 역시 분석 결과에 큰 영향을 미칠 수 있으므로, 이를 탐지하고 처리하는 것이 중요하다. 또한, 중복된 데이터를 제거하고, 잘못된 데이터를 수정하는 작업도 포함된다. 이 모든 작업은 데이터를 신뢰할 수 있는 상태로 만드는 데 필수적이다.
다음으로는 데이터 변환 단계이다. 데이터를 정규화하거나 표준화하여 모델의 성능을 최적화하고, 범주형 데이터를 숫자로 변환하는 등 데이터의 형식을 일관되게 맞추는 과정이다. 이를 통해 모델이 데이터의 특정 변수에 치우치지 않고, 균형 잡힌 성능을 발휘할 수 있다. 또한, 날짜 데이터를 변환하여 유의미한 피처를 생성하고, 로그 변환을 통해 데이터의 분포를 정규분포에 가깝게 만드는 작업도 포함된다.
데이터 변환이 끝나면 피처 엔지니어링 단계가 이어진다. 이는 기존 데이터를 바탕으로 새로운 유의미한 변수를 생성하고, 모델 성능에 크게 기여하지 않는 변수를 제거하는 과정이다. 이를 통해 모델의 복잡도를 줄이고, 성능을 향상시킬 수 있다.
마지막으로, 데이터를 훈련 데이터와 테스트 데이터로 분할하고, 교차 검증을 통해 모델의 일반화 성능을 확인하는 단계니다. 이는 모델이 실제 데이터를 잘 예측할 수 있는지를 평가하는 데 중요한 과정이다.
이를 종합해 보면 데이터가 올바르게 전처리되지 않으면, 아무리 좋은 알고리즘과 모델을 사용해도 좋은 결과를 기대할 수 없다. 데이터 전처리 과정은 데이터의 품질을 높이고, 분석 결과의 정확성을 향상시키며, 알고리즘의 성능을 최적화하는데 필수적인 역할을 한다. 따라서, 데이터 과학자라면 데이터 전처리의 중요성을 깊이 인식하고, 이를 철저히 수행해야 한다.
반응형
'강화학습' 카테고리의 다른 글
| 데이터전처리와 강화학습의 관계 (0) | 2024.06.17 |
|---|---|
| 데이터 전처리: 완벽한 데이터 분석의 첫걸음 (0) | 2024.06.10 |
| 데이터 전처리 단계와 참조 무결성의 관계 (0) | 2024.05.23 |
| 데이터 전처리는 어떻게 할까? (0) | 2024.05.22 |
| 인공지능 구현에서 데이터 전처리의 필요성 (0) | 2024.05.21 |




